IR0 Kernel - Overview
The purpose of this "wiki", web documentation, guide, however you call it, is to use it as a
personal memory aid
for kernel development.
It doesn't have to be an ultra-aesthetic page, but I'm trying hard so it doesn't show that I made it
with vanilla html, css and js like some amateur project
that's out there.
A minimally functional operating system kernel (all the Kernel Space plus a minimal user space)
can easily run in 15,000 lines of code, so as you'll see;
it's humanly impossible to memorize and understand the entire kernel flow by myself. Besides, there
are many complex subsystems working together at a low level to mediate between hardware and
software.
This calculation is automatic and is done through an API that counts the number of lines of code in the kernel (.c, .h, .asm, .rs, and .cpp)
This deserves a star on the repo
Contributors
What is IR0?
IR0 is a multipurpose operating system kernel developed
from scratch for the x86-64 architecture, written in C,
C++,
Rust, and ASM. The kernel core is in C, device drivers in Rust
(for memory safety), and advanced components like schedulers in C++ (for templates and RAII).
I'm creating it to learn more about operating systems and be able to use it as raw material
for another project that replicates WSL2 but with my own kernel.
I don't rule out scaling it enough to make it usable in minimal servers or even IoT,
but I understand that's in the very long term.
This
is its GitHub Repository.
Discord
community
Main Implemented Features
- ✅ Monolithic modular kernel for x86-64 architecture
- ✅ Complete virtual memory management with paging (MMU)
- ✅ Complete interrupt and exception system (64 IDT vectors)
- ✅ Round Robin Scheduler (simple implementation)
- ✅ Complete process system with fork(), exit(), waitpid()
- ✅ 23 implemented syscalls (from basic to memory management)
- ✅ Complete MINIX filesystem with VFS (Virtual File System)
- ✅ Hardware drivers: PS/2 (keyboard/mouse), ATA/IDE, Sound Blaster 16, VGA
- ✅ Interactive shell in Ring 3 with built-in commands
- ✅ Freestanding LibC with printf(), malloc(), free()
- ✅ Multi-target build system (Desktop/Server/IoT/Embedded)
Project Status
Version: 0.0.1 pre-release 3
Architecture: x86-64 (primary), x86-32 (experimental), ARM32 (planned)
Bootloader: GRUB
License: GNU General Public License v3.0
Development Status: Active Development
License: GNU GPL v3.0
Type: Monolithic Modular Kernel
ASM Syntax: Intel (NASM)
System Architecture
Design Philosophy
IR0 implements a modular monolithic kernel architecture where:
- Core kernel services reside in Ring 0 (kernel space)
- User applications execute in Ring 3 (user space)
- System calls provide the interface between user and kernel space
- Modular design allows selective compilation of subsystems
IR0 Kernel Architecture Diagram
User Space (Ring 3)
Interactive Shell
LibC (IR0)
User Programs
ELF Loader
Kernel Space (Ring 0) - IR0
System Interface
23 Syscalls (IR0)
INT 0x80 Handler
Init System (PID 1)
Process & Memory
Round Robin Scheduler
Virtual Memory (MMU)
Heap Allocator
Process Manager
File System
VFS Layer
MINIX Filesystem
File Operations
Hardware Drivers
PS/2 (Keyboard/Mouse)
ATA/IDE Storage
Sound Blaster 16
VGA/VBE Video
Interrupts & Timers
IDT (64 vectors)
PIC Remapping
Timer Cascade
DMA Controller
Network (Planned)
Custom TCP/IP (Design)
Socket Interface
Ethernet Drivers
Hardware
CPU x86-64
RAM (MMU)
ATA/IDE Disks
PS/2 Devices
Sound Blaster
VGA/VBE
User Space (Ring 3) - Shell, LibC and user programs
Kernel Space (Ring 0) - IR0 monolithic modular kernel
Hardware - Supported physical components
Architecture and "Philosophy" of the project
Unlike kernels such as Microsoft's NT kernel (Hybrid), Redox-OS
(Microkernel),
or the same MINIX kernel (microkernel), IR0 is based on a more similar
architecture
to what Linux has, which is monolithic.
However, my main argument is that of performance. I understand that someone could come and
point out that, like any monolith, if a subcomponent breaks, the entire system crashes (and
they would be right)
but what I respond to that is "What good does it do me that the kernel supports continuing
without
filesystem if I can't do anything practical without it?", that is, it doesn't make sense
that the
kernel
continues functioning without one of its key components running.
That's why I don't see a better alternative (for now) than the monolithic pattern. And it also saves me from having to
interconnect
key subsystems with each other via IPC, which impacts performance of the Operating System. It's not
perfect, but it's stable. It's not entirely traceable and requires scaling little by little, but if
it scales well it performs a lot.
However, I also have disagreements with the UNIX philosophy. They (among other things and very briefly)
consider
that if something fails, let it fail well. Which in kernel terms would be: If the
scheduler breaks, Panic() directly. If you have memory corruption (in kernel space),
Panic.
And it's not that I question it for no reason, I simply ask (although without solutions yet) "Why
not rescue the system during Panic()?, or at least try".
Beyond the philosophical point and to summarize, the kernel is monolithic because it's more
performant and
I feel that the key pieces of the kernel must work without overhead.
However, if in the future I needed to integrate some specific subsystem in a hybrid way,
I would surely be pragmatic.
Kernel Space is sacred
I know I talk as if IR0 were used by thousands of people and all the history, but I'm going to give
myself the luxury of opining
about it.
So, the point is that kernel space has to be only habitable by subsystems
that work in that Environment,
nothing else.
I understand that there are certain manufacturers concerned about their clients'
security who,
coincidentally, have access to every interruption that the user makes (they know what keys you
press,
your session time every time you turn on the computer, etc.) And all that because they have
software running in the kernel space with all the privileges that implies.
RING 0 is only for the kernel. Everything that comes from RING 3
communicates with syscalls(), end of statement.
Network Approach: Basic but Functional
For IR0 to work as support for basic servers and IoT applications, I need
fundamental network support but without the massive complexity of Linux's complete
stack.
In the Linux Kernel there are more or less 1,500,000 lines of code ONLY THE COMPLETE
NETWORK STACK. Instead of trying to port all of that, I've decided to use a more
pragmatic approach:
Custom lightweight stack (planned):
- In-house IPv4 + TCP/UDP implementation written specifically for IR0
- Socket interface aligned with our syscall layer
- Ethernet drivers integrated with the IR0 HAL
- Minimal feature set focused on reliability and learning
Advantages of building our own stack
- Total ownership and easier auditing of the codebase
- No dependence on Linux internals or third-party stacks
- Ability to evolve the stack at the same pace as the kernel
- Maintains the project lean and manageable
- Helps reinforce the educational goal of IR0
Directory Structure
How the file structure can change constantly, I prefer you consult it in the GitHub Repository.
Branch Management
Git Workflow
For that I use 3 main git branches in the process: mainline, dev and feature (which although feature is not in the repository, it's the one used as convention for integrating new code). Where only mainline and dev are the only 2 upstream branches.
experimental is a branch divergent to dev, and feature is the branch that is created to send contributions.
mainline
STABLE
- Main branch with stable and tested code.
Characteristics
- Only tested and functional code
- Complete documentation
- My base for rc's.
- mainline is sacred, since this branch has to compile and boot always. It's the most stable of the two upstream branches.
dev
STAGING
- Active development branch where new features are implemented and tested.
Characteristics:
- It's the mirror of mainline.
- What gets merged here doesn't have to go to mainline.
- New features in development that convinced me of feature
- Code patches, refactors and optimizations
- It can contain temporary bugs that are resolved one way or another in this branch.
feature
DEVELOPMENT
- I add it because it's the branch where feats are created that later go to upstream merging to dev. It's the most unstable of all because it's where new code is integrated that must also be tested and reviewed before reaching merge.
Characteristics:
- This is where I start to implement new functionalities or patches
- It's the first one that gets debugged.
- It's the one you would create when you fork the repo.
- It's expected to compile before going to dev.
experimental
MISC
- In this branch, features are integrated unstable enough to end up in mainline but that may have potential in the future.
Characteristics:
- It's a pure testing branch, it has nothing to do with stable upstream branches
- Here fall the features and experiments that don't reach mainline
- Things that aren't tested in operating systems or new ideas
- Stability is not so important in this branch
- If they are tested enough without breaking anything, they may or may not merge to mainline first passing through dev again.
How is merging from feature to mainline?
Then, you make PR to the upstream dev branch (not to mainline) and the review and merge is done if applicable.
The merge to mainline depends on how aligned with the project I consider the feature is.
Not even some of my own implementations would I merge directly to mainline for this same reason.
IR0 Kernel Subsystems
⚙️ Process Management
Location: kernel/process.c, kernel/process.h
The process management subsystem handles the complete lifecycle of processes in the IR0 kernel, including creation, execution, termination, and parent-child relationships. It provides process isolation through separate page directories and supports signal-based inter-process communication.
Process Structure
Each process is represented by a process_t structure containing:
- Task Context - CPU register state (RAX, RBX, RCX, RDX, RSI, RDI, RSP, RBP, RIP, RFLAGS, segments)
- Process ID - Unique identifier (starts from PID 2, PID 1 is init)
- Parent Process ID - Parent process identifier
- Process State - READY, RUNNING, BLOCKED, or ZOMBIE
- Execution Mode - KERNEL_MODE or USER_MODE
- Page Directory - Virtual memory isolation (separate page tables per process)
- Memory Layout - Stack, heap boundaries, and memory mappings
- File Descriptors - Table of open file descriptors (max 32 per process)
- Signal Pending - Bitmask of pending signals
Process States
- PROCESS_READY (0) - Process is ready to run, waiting to be scheduled
- PROCESS_RUNNING (1) - Process is currently executing on CPU
- PROCESS_BLOCKED (2) - Process is waiting for I/O or other events
- PROCESS_ZOMBIE (3) - Process has terminated but parent hasn't called
wait()yet
Process Lifecycle
Process Creation
process_spawn() - Creates a new process deterministically with a specified entry point and name:
- Creates isolated process with separate page directory
- Allocates 8KB stack
- Sets up CPU context for user mode (Ring 3)
- Registers process in scheduler
- Assigns sequential PID (starting from 2)
- Sets parent to current process
Process Termination
process_exit() - Terminates the current process:
- Sets process state to ZOMBIE
- Stores exit code
- Reparents orphaned children to init (PID 1)
- Sends SIGCHLD signal to parent process
- Halts execution until reaped by parent
Process Waiting
process_wait() - Waits for a child process to terminate and retrieves its exit status:
- Searches for zombie child process with matching PID
- Retrieves exit code and removes from process list
- Returns child PID on success
Signal Integration
The process subsystem integrates with the signal system for inter-process communication and error handling:
- CPU Exceptions → Signals: SIGSEGV (page fault), SIGFPE (divide by zero), SIGILL (invalid opcode)
- Termination Signals: SIGKILL, SIGTERM, SIGINT, SIGQUIT
- Process Control: SIGCHLD (child terminated), SIGSTOP, SIGCONT
- Signals are handled before each context switch
- Fatal signals terminate the process
Memory Isolation
Each process has its own page directory (CR3 register) for memory isolation:
- Kernel Space - Shared across all processes (identity mapped)
- User Space - Process-specific virtual address space
- Stack - Private 8KB stack per process
- Heap - Managed by
brk()syscall (per-process heap)
🛡️ Memory Management
Location: mm/pmm.c, mm/allocator.c, mm/paging.c
The memory management subsystem provides three layers of memory allocation and management: Physical Memory Manager (PMM) for frame allocation, heap allocator for dynamic kernel memory, and paging system for virtual memory and process isolation.
Physical Memory Manager (PMM)
Location: mm/pmm.h, mm/pmm.c
The PMM manages physical memory frames (4KB pages) using a bitmap-based allocator:
- Memory Region: 8MB to 32MB (24MB total, ~6000 frames)
- Algorithm: First-fit bitmap search
- Operations:
pmm_alloc_frame()- Allocates a frame,pmm_free_frame()- Deallocates a frame - Statistics:
pmm_stats()- Provides total/used/free frame counts - Encoding: 1 bit per 4KB frame (1 = used, 0 = free)
Heap Allocator
Location: includes/ir0/kmem.h, mm/allocator.c
Dynamic memory allocation for kernel code using a free-list with boundary tags:
- Algorithm: Free-list with boundary tags for efficient coalescing
- Allocation: First-fit search with block splitting
- Deallocation: Forward and backward coalescing (O(1) operations)
- API:
kmalloc(),kmalloc_aligned(),krealloc(),kfree(),kfree_aligned() - Structure: Each block has header (start) and footer (end) with size and free status
Paging System
Location: mm/paging.h, mm/paging.c
Virtual memory management and process isolation through separate page directories:
- Page Sizes: 4KB pages (standard), 2MB pages (identity mapping), 1GB pages (defined but unused)
- x86-64 Structure: PML4 → PDPT → PD → PT (4-level paging)
- Page Flags: PRESENT, RW, USER, WRITETHROUGH, CACHE_DISABLE, ACCESSED, DIRTY, SIZE_2MB, GLOBAL
- Process Isolation: Each process has its own page directory (CR3 register)
- Identity Mapping: First 16MB using 2MB pages for kernel space
- Operations:
map_page(),unmap_page(),create_process_page_directory()
Memory Regions
Kernel Memory Map
0x000000 - 0x100000 Boot code, kernel code 0x100000 - 0x800000 Kernel heap (grows upward) 0x800000 - 0x2000000 PMM managed frames (8MB-32MB, 24MB) 0x2000000+ Kernel data, stacks
Process Memory Layout
- Code Segment - ELF binary loaded into user space
- Stack - 8KB default, grows downward from high address
- Heap - Grows upward from low address, managed by
brk()syscall - Page Directory - Isolated virtual address space
Implementation Notes
- No Copy-on-Write: Fork operations don't use COW (intentional limitation)
- No Swap: All memory is physical (no disk swapping)
- Simple Algorithms: First-fit for both PMM and heap (not optimized)
- No NUMA: Assumes uniform memory access
- Single CPU: No SMP-aware memory management
🔄 Scheduler
Location: kernel/rr_sched.c, kernel/rr_sched.h
The scheduling subsystem manages CPU time allocation among processes. IR0 currently implements a simple Round-Robin scheduler that provides fair time-sharing among all ready processes. The scheduler integrates with the process management and signal handling subsystems.
Round-Robin Algorithm
The Round-Robin scheduler maintains a circular linked list of processes:
- Process Queue: Linked list of
rr_task_tnodes, each containing aprocess_t* - Current Pointer: Points to the currently executing process node
- Circular Selection: Each context switch advances to the next node, wrapping to head when reaching tail
Operations
Adding Processes
rr_add_process() - Adds a process to the scheduler queue:
- Validates process pointer
- Allocates new
rr_task_tnode - Sets process state to PROCESS_READY
- Appends to tail of queue
Scheduling Next Process
rr_schedule_next() - Performs context switch to next process:
- Selection: Advances to next node (wraps to head if at tail)
- State Update: Previous → PROCESS_READY, Next → PROCESS_RUNNING
- Signal Handling: Calls
handle_signals()before context switch - Context Switch: First switch uses
jmp_ring3(), subsequent useswitch_context_x64()
Context Switching
Context switching saves/restores CPU state (kernel/scheduler/switch/switch_x64.asm):
- Saved Registers: RAX-R15, RSP, RBP, RIP, RFLAGS, segments (CS, DS, ES, FS, GS, SS)
- Memory Isolation: Switches page directory (CR3 register) for process isolation
- Process: Save current → Load CR3 → Load segments → Load registers → Execute IRETQ
Time Slicing
Current implementation:
- No explicit time slicing - Processes run until they voluntarily yield, block on I/O, exit, or receive a blocking/terminating signal
- Future: Integration with timer interrupts for preemptive scheduling with time slices (e.g., 10ms per process)
Signal Integration
The scheduler calls handle_signals() before each context switch:
- Checks for pending signals in current process
- Handles signals in priority order (SIGKILL, CPU exceptions, termination signals)
- Clears signal bitmask after handling
- Ensures signals are processed synchronously before process execution continues
Limitations
- No Priorities: All processes have equal priority
- No Nice Values: Cannot adjust process priority
- Cooperative Multitasking: Processes must yield voluntarily
- No Preemption: Timer interrupts don't trigger context switches
- Simple Queue: Linked list, not optimized for many processes
- No Load Balancing: Single CPU only (no SMP support)
Project Status
Version: v0.0.01 pre-release candidate 1
Architecture: x86-64 (primary), x86-32 (experimental), ARM (in development)
License: GNU GPL v3.0
Type: Monolithic Modular Kernel
🏗️ Core Architecture
✅ Kernel Architecture
- Monolithic modular design with HAL abstraction
- Multi-target build system (Desktop/Server/IoT/Embedded)
- Ring 0 (kernel) / Ring 3 (user) separation
- x86-64 primary support with multi-arch framework
- Freestanding C environment with custom libc
✅ Boot System
- GRUB multiboot specification compliance
- x86-64 long mode initialization
- GDT (Global Descriptor Table) setup
- TSS (Task State Segment) configuration
- IDT (Interrupt Descriptor Table) with 64 entries
✅ Memory Management
- Virtual memory with paging (MMU)
- Kernel heap allocator (simple + advanced WIP)
- Memory protection (Ring 0/3 isolation)
- Memory layout: Kernel (1MB-8MB), Heap (8MB-32MB), User (1GB+)
- Page fault handling with CR2 fault address reading
⚙️ Process Management
✅ Process System
- Complete process lifecycle management
- Process states: READY, RUNNING, BLOCKED, ZOMBIE
- PID assignment starting from PID 1
- Process creation with fork() syscall
- Process termination with exit() syscall
- Parent-child relationships with waitpid()
✅ Scheduler
- Round Robin scheduler with fixed quantum
- Single ready queue rotating runnable tasks
- PIT timer interrupts drive preemption points
- Integrates directly with the existing process lifecycle
- Serves as the base for the upcoming priority scheduler
✅ Init System
- PID 1 init process (mini-systemd)
- Service management and respawning
- User mode switching from kernel
- Shell service management
🔧 System Calls
✅ Syscall Interface (23 syscalls implemented)
SYS_EXIT(0) - Process termination SYS_WRITE(1) - Write to file descriptor SYS_READ(2) - Read from file descriptor SYS_GETPID(3) - Get process ID SYS_GETPPID(4) - Get parent process ID SYS_LS(5) - List directory contents SYS_MKDIR(6) - Create directory SYS_PS(7) - Show process list SYS_WRITE_FILE(8) - Write file to filesystem SYS_CAT(9) - Display file contents SYS_TOUCH(10) - Create empty file SYS_RM(11) - Remove file SYS_FORK(12) - Create child process SYS_WAITPID(13) - Wait for child process SYS_RMDIR(40) - Remove directory SYS_MALLOC_TEST(50) - Memory allocation test SYS_BRK(51) - Change heap break SYS_SBRK(52) - Increment heap break SYS_MMAP(53) - Memory mapping SYS_MUNMAP(54) - Unmap memory SYS_MPROTECT(55) - Change memory protection SYS_EXEC(56) - Execute program
✅ Syscall Mechanism
Location: kernel/syscalls.c, arch/x86-64/asm/syscall_entry_64.asm
Implementation: 45+ system calls implemented with INT 0x80 interface (legacy) and SYSCALL/SYSRET (x86-64)
- INT 0x80 software interrupt interface
- Register-based parameter passing
- Kernel/user mode transition
- Error handling and return values
⚡ Interrupt System
✅ Interrupt Handling
- Complete IDT setup with 64 interrupt vectors
- PIC (Programmable Interrupt Controller) remapping
- ISR (Interrupt Service Routines) in assembly
- IRQ handling for hardware devices
- Timer interrupt integration
- Keyboard interrupt (IRQ 1)
- Mouse interrupt (IRQ 12)
- Audio interrupt (IRQ 5)
✅ Exception Handling
- Page fault handler with CR2 address reading
- General protection fault handling
- Division by zero exception
- Invalid opcode exception
- Stack fault handling
🖥️ Hardware Drivers
✅ Input Devices
- PS/2 Keyboard driver with circular buffer
- PS/2 Mouse driver with 3/5 button + scroll wheel support
- Mouse type detection (standard/wheel/5-button)
- Configurable sample rates and resolution
✅ Storage Devices
- ATA/IDE hard disk driver
- CD-ROM support
- Basic disk I/O operations
- Sector-based read/write
✅ Audio System
- Sound Blaster 16 driver
- 8-bit/16-bit audio support
- Mono/Stereo playback
- DMA-based audio transfer (channels 1 and 5)
- Volume control (master and PCM)
- Sample rate configuration
- Audio format detection
✅ Video System
- VGA text mode (80x25)
- VBE (VESA BIOS Extensions) graphics support
- Framebuffer access
- Basic graphics primitives
✅ Serial Communication
- COM1/COM2 serial port drivers
- Debug output via serial
- Configurable baud rates
- Serial interrupt handling
✅ Timer Systems
- PIT (Programmable Interval Timer)
- RTC (Real Time Clock)
- HPET (High Precision Event Timer)
- LAPIC (Local APIC Timer)
- Unified clock system abstraction
- Timer cascade with best available timer selection
✅ DMA Controller
- 8-channel DMA support (0-7)
- 8-bit and 16-bit transfer modes
- Audio DMA integration
- Channel enable/disable control
📁 File System
✅ Virtual File System (VFS)
Location: fs/
VFS Architecture Components:
- VFS Abstraction Layer (
vfs.c,vfs.h) - Unified interface for all filesystems - VFS Simple Implementation (
vfs_simple.c) - Simplified VFS operations - Path Resolution (
path.c) - Path parsing and resolution - File Operations (
kernel/fs/file.c) - File descriptor management
Supported Filesystems:
- MINIX Filesystem (
fs/minix_fs.c,fs/minix_fs.h) - Full MINIX v1/v2 support with directory and file operations - RAM Filesystem - In-memory filesystem for temporary storage
✅ MINIX Filesystem
- Complete MINIX filesystem implementation
- Inode-based file storage
- Directory structure support
- File creation, deletion, and modification
- Integrated with VFS layer
✅ File Operations
- File creation (touch)
- File deletion (rm)
- Directory creation (mkdir)
- Directory removal (rmdir)
- File content display (cat)
- Directory listing (ls)
- File writing capabilities
👤 User Space
✅ C Library (LibC)
- Freestanding C library implementation
- Standard headers: stdio.h, stdlib.h, unistd.h, stdint.h, stddef.h
- I/O functions: printf(), puts(), putchar()
- Memory functions: malloc(), free()
- Process functions: exit(), getpid()
- System call wrappers
✅ Printf Implementation
- Format specifiers: %d (integers), %s (strings), %c (characters)
- Variable argument support
- Output to stdout
✅ User Programs
- Echo command implementation
- Shell integration for user programs
- ELF loader (basic implementation)
🐚 Shell System
✅ Interactive Shell
- Command-line interface in Ring 3 (user mode)
- Built-in commands: ls, ps, cat, mkdir, rmdir, touch, rm, fork, clear, help, exit, malloc, sbrk, exec
✅ Shell Features
- Command parsing and execution
- Process management integration
- Filesystem operation support
- Memory management testing
- Error handling and feedback
🌐 Network System
� Custom TCP/IP Stack (Planned)
- Designing an in-house IPv4/TCP/UDP pipeline
- Lightweight socket interface wired into IR0 syscalls
- Ethernet driver bring-up before higher-level protocols
- Focus on correctness over feature count for the first release
Status: There is no network connectivity yet; groundwork is in progress to code the entire stack ourselves.
🔧 Build System
✅ Multi-Target Build
- Desktop target (full features, 256MB heap, 1024 processes)
- Server target (optimized networking, 1GB heap, 4096 processes)
- IoT target (power management, 16MB heap, 64 processes)
- Embedded target (minimal features, 4MB heap, 16 processes)
✅ Multi-Architecture
- x86-64 production support
- x86-32 experimental support
- ARM development framework
- Architecture abstraction layer (HAL)
⚠️ Current Limitations
❌ Not Yet Implemented
- SMP (Symmetric Multiprocessing) support
- Dynamic kernel modules
- Advanced IPC (pipes, message queues)
- Network stack (TCP/IP)
- USB support
- Advanced GUI/Window manager
- Signal handling
- Copy-on-write memory
- Swap memory support
- Advanced filesystem features (ext2/3/4)
⚠️ Known Issues
- Fork() context switching needs refinement
- Limited ELF loader functionality
- No zombie process reaping in init
- Basic memory allocator (advanced versions in development)
- Single CPU support only
📊 Technical Specifications
Memory Layout
Kernel Space: 0x100000 - 0x800000 (1MB-8MB) Heap Space: 0x800000 - 0x2000000 (8MB-32MB, 24MB total) User Space: 0x40000000+ (1GB+)
Performance Metrics
- Context switch time: ~microseconds (assembly optimized)
- Scheduler complexity: O(log n) with Red-Black Tree
- Memory allocation: O(1) for simple allocator
- Interrupt latency: Minimal with optimized ISRs
Resource Limits (Desktop Target)
- Maximum processes: 1024
- Maximum threads: 4096
- Heap size: 256MB
- Scheduler quantum: 10ms
- I/O buffer size: 64KB
🎯 Roadmap
Short Term (Next Release)
- Fix fork() context switching issues
- Implement proper zombie reaping
- Bootstrap the in-house TCP/IP stack
- Improve ELF loader
- Add USB framework
Medium Term
- SMP support
- Advanced GUI system
- Basic networking expansion (more protocols, optimizations)
- Dynamic kernel modules
- Advanced IPC mechanisms
Long Term
- Native application support (Doom, GCC, Bash)
- Complete POSIX compatibility
- Advanced filesystem support
- Hardware abstraction improvements
- Performance optimizations
Development Guide
- This section is in case someone is interested in contributing to the project.
They are not
strict rules, they are simply recommendations
to make it more bearable.
What do you need to know to contribute?
More than anything the following:Similarly, you don't have to be an expert to contribute to the kernel. Simply with having the desire to learn/study about what you're going to contribute is more than enough.
Environment Setup
Required Dependencies:
NOTE: Since this project is a kernel, it's Freestanding. That means you
can't include libraries like
stdio.h to do a
print(), write(), etc. because there's no operating system that
responds to those functions . You are the
operating system. that's why, in the repo I have the folder of dependencies "includes".
How do I write code?
Naming Conventions:
- Functions:
snake_case() - Macros:
UPPER_CASE - Structs:
struct_name_t - Global variables:
g_variable_name - Constants:
CONSTANT_NAME - includes:
#INCLUDE -ir0/Lib.h -(are being migrated to that format)
Coding Style & Conventions:
We try to follow the Linux kernel coding style, but with some specific adaptations for this project. These are desirable conventions, not strict rules (except for the brace style).
- Allman Style Braces (Important): We use the Allman style (braces on a new line). This is the most important formatting rule.
- Comments: We prefer multi-line comments
/* ... */over single-line//. - Conditionals: Single-line
ifstatements should not use braces. - Error Handling: We use
gotofor cleanup logic when multiple exit points share the same cleanup code.
/*
* Example of a function following IR0 conventions
* Note the Allman style braces and multi-line comments
*/
int process_data(struct data_t *data)
{
if (!data)
return -1; /* Single line if without braces */
char *buffer = kmalloc(1024);
if (!buffer)
{
/*
* Braces are used here because the block
* contains multiple lines or is complex
*/
return -ENOMEM;
}
if (prepare_buffer(buffer) < 0)
goto cleanup; /* Use goto for error handling/cleanup */
/* ... processing logic ... */
kfree(buffer);
return 0;
cleanup:
kfree(buffer);
return -1;
}Header Files (.h):
Header files should contain function prototypes, struct definitions, and detailed documentation in comments.
#ifndef _IR0_EXAMPLE_H
#define _IR0_EXAMPLE_H
/*
* struct example_t - Represents an example structure
* @id: Unique identifier
* @value: Associated value
*/
typedef struct
{
int id;
int value;
} example_t;
/*
* process_example - Processes the example structure
* @ex: Pointer to the structure
* Returns: 0 on success, negative error code on failure
*/
int process_example(example_t *ex);
#endif🔧 Setup and Compilation
Dependency Verification
IMPORTANT: Before compiling, it's recommended to verify that all dependencies are correctly installed:
make deptest
This command will verify the presence of all necessary tools:
- Essential Tools: GCC, NASM, LD, Make, QEMU, GRUB
- Multi-Language Compilers (REQUIRED): G++/Clang++, Rustc, Cargo, rust-src
- Cross-Compilation: MinGW-w64 (for compiling to Windows from Linux)
- Python: Python 3, tkinter, PIL/Pillow
The script automatically detects your platform and provides specific installation instructions if any tool is missing.
Required Tools
Essential:
- GCC - C Compiler
- NASM - Assembler
- LD - ELF x86-64 Linker
- Make - Build automation
Runtime:
- QEMU (qemu-system-x86_64) - Emulator
- GRUB (grub-mkrescue) - Bootable ISO creation
Optional:
- Python 3 - Kernel configuration system
Multi-Language Support (REQUIRED since v0.0.1-pre.1):
- G++ / Clang++ - C++ compiler (for advanced kernel components)
- Rustc + Cargo - Rust compiler (for device drivers)
- rust-src - Rust component for no_std development
Multi-Language Support
IR0 now supports development in three languages:
- C - Kernel core, memory management, system calls
- Rust - Device drivers (network, storage, USB) with memory safety
- C++ - Advanced components (schedulers, protocol stacks) with templates and RAII
Installing Rust:
# Install Rust curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh # Add required components rustup component add rust-src rustup target add x86_64-unknown-none # Verify installation rustc --version cargo --version
Installing C++:
# Debian/Ubuntu sudo apt-get install g++ # Arch Linux sudo pacman -S gcc # Verify installation g++ --version
Installation on Linux
# Debian/Ubuntu sudo apt-get install build-essential nasm qemu-system-x86 grub-pc-bin python3 # Arch Linux sudo pacman -S base-devel nasm qemu grub python
Compilation Commands
| Command | Description |
|---|---|
make ir0 |
Complete build: kernel ISO + userspace programs |
make kernel-x64.bin |
Build only the kernel binary |
make kernel-x64.iso |
Create bootable ISO image |
make userspace-programs |
Build only userspace programs |
make clean |
Clean all build artifacts |
make userspace-clean |
Clean only userspace programs |
Running in QEMU
| Command | Description |
|---|---|
make run |
Run with GUI + virtual disk (recommended) |
make run-debug |
Run with GUI + serial debug output |
make debug |
Run with detailed QEMU logging |
make run-nodisk |
Run without virtual disk |
make run-console |
Run in console mode (no GUI) |
QEMU Configuration:
- Memory: 512MB
- Display: GTK (configurable to SDL2)
- Serial: stdio (for debug)
- Flags:
-no-reboot -no-shutdown - Debug log:
qemu_debug.log
Virtual Disk Management
| Command | Description |
|---|---|
make create-disk |
Create virtual disk image (disk.img) |
make delete-disk |
Delete virtual disk image |
Disk specifications:
- Size: 100MB (configurable)
- Format: RAW
- Filesystem: MINIX
- Script:
scripts/create_disk.sh
Utility Commands
| Command | Description |
|---|---|
make deptest |
Verify all system dependencies |
make help |
Show complete Makefile help |
make menuconfig |
Launch kernel configuration (ncurses) |
make unibuild FILE=<file> |
Compile individual file |
unibuild System - Multi-Language Compilation:
The unibuild system now supports compiling files in C, C++, and Rust with specific flags:
# Compile C files (default) make unibuild FILE=kernel/memory/kmalloc.c # Compile C++ files make unibuild -cpp FILE=kernel/scheduler/advanced_sched.cpp # Compile Rust drivers make unibuild -rust FILE=drivers/network/rtl8139.rs # Cross-compile to Windows (from Linux) make unibuild -win FILE=kernel/file.c make unibuild -win -cpp FILE=kernel/component.cpp make unibuild -win -rust FILE=drivers/driver.rs # Compile multiple files make unibuild FILES="fs/ramfs.c fs/vfs.c"
Available flags:
-cpp- Use C++ compiler (g++)-rust- Use Rust compiler (rustc)-win- Cross-compile to Windows using MinGW-w64
Flags can be combined for different use cases (e.g., -win -cpp to cross-compile C++ to
Windows).
Recommended Workflow
- Verify dependencies:
make deptest - Build the kernel:
make ir0 - Create virtual disk:
make create-disk(first time) - Run in QEMU:
make run - For debugging:
make run-debug
Kernel Subsystems
- This section details the main subsystems that compose the IR0 kernel,
their current development status and technical characteristics of each one.
The best way to understand the internal operation is by reviewing the source code in the
GitHub Repository.
🔄 Scheduler
The scheduler is the heart of the multiprocessing system. Currently implements a simple Round-Robin algorithm as fallback, but the goal is to migrate to a preemptive scheduler with priority scheme similar to Linux's CFS (Completely Fair Scheduler).
Current Features:
- Round-Robin algorithm with fixed quantum
- Support for multiple priority levels
- Basic process state management (Ready, Running, Blocked)
- Optimized context switching in assembly
Upcoming Improvements:
- Preemptive scheduler implementation
- CFS algorithm for fair CPU distribution
- Real-time scheduling support
- Load balancing between cores
Files: scheduler/scheduler.c, scheduler/task.h, scheduler/switch/switch.asm
💾 Filesystem
Own filesystem based on EXT2 but with modern innovations. The distinctive feature is the integration of a vectorial database to optimize file search and indexing operations.
Technical Features:
- Hierarchical directory structure
- Support for files up to 2TB
- Journaling for failure recovery
- Transparent file compression
- Vectorial indexing for fast searches
Innovations:
- Integration with libvictor for semantic searches
- Intelligent cache based on access patterns
- Extended metadata support
- File-level encryption
Status: Active development
Files: fs/ext2.c, fs/victor_index.c, fs/journal.c
⚡ Interrupt System
Robust interrupt and exception handling system that ensures kernel stability and provides a clean interface for handling hardware and software events.
Main Components:
- IDT (Interrupt Descriptor Table): 256-entry table for interrupt mapping
- ISR (Interrupt Service Routines): Optimized handlers in assembly
- Exception Handler: Processor exception handling
- IRQ Manager: Hardware interrupt management
Features:
- Complete page fault handling with automatic recovery
- Nested interrupts with priorities
- Deferred interrupt processing
- Interrupt coalescing for optimization
Files: interrupt/idt.c, interrupt/interrupt.asm, interrupt/isr_handlers.c, interrupt/irq.c
🚀 Boot Subsystem
Initialization system that prepares the environment for kernel execution, handling the transition from bootloader to user space.
Boot Phases:
- Phase 1: Processor initialization and protected mode
- Phase 2: Paging and virtual memory configuration
- Phase 3: Critical subsystems initialization
- Phase 4: First process loading (init)
Features:
- Support for multiple architectures (x86-64, ARM64)
- Independent bootloader with UEFI support
- Automatic recovery from boot failures
- Integrated recovery mode
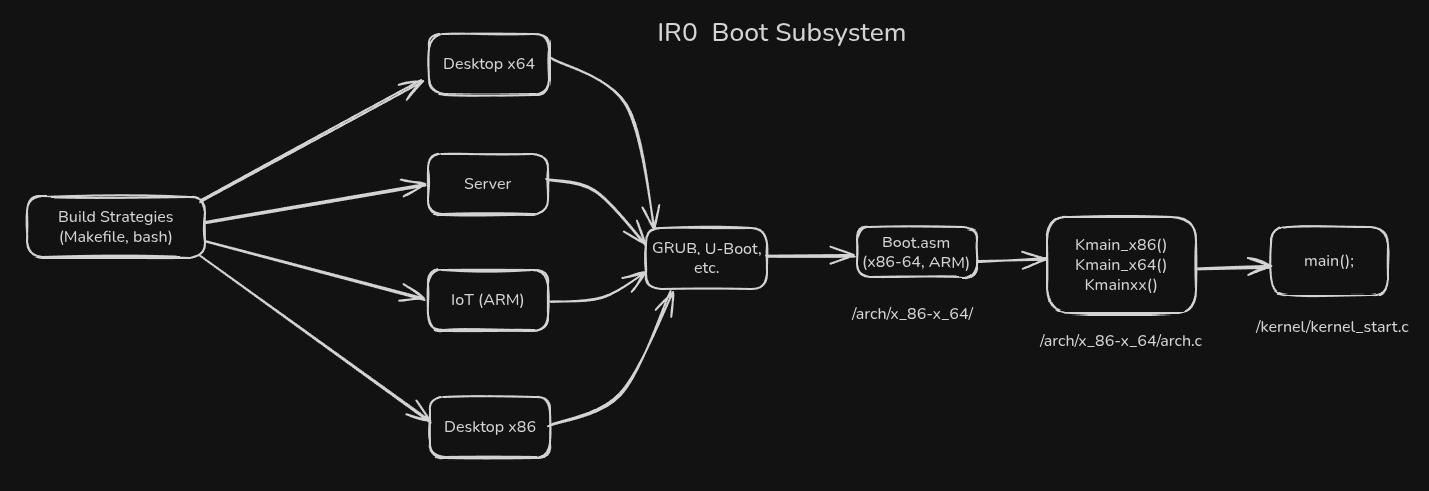
Files: boot/boot.asm, boot/kmain.c, boot/arch.c, boot/kernel_start.c
🛡️ Memory Management
Advanced memory management system that provides process isolation, performance optimization and protection against unauthorized access.
Components:
- Memory Manager: Physical and virtual page management
- Page Allocator: Efficient memory allocation
- Slab Allocator: Optimization for small objects
- Memory Protection: Access control and permissions
Features:
- 4-level paging (48-bit addressing)
- Transparent memory compression
- NUMA awareness for multi-socket systems
- Memory deduplication
Files: mm/page_alloc.c, mm/slab.c, mm/vmalloc.c, mm/protection.c
🌐 Network Subsystem
We are drafting a custom TCP/IP stack written 100% by us, without importing Linux code or external libraries. The focus is on a maintainable, well-understood implementation tailored to IR0.
Initial Scope (planned):
- Ethernet + ARP + IPv4 support
- Minimal TCP and UDP implementations
- Socket API surfaced through existing syscalls
- Driver layer for a handful of NICs
Future Goals:
- IPv6 once IPv4 path is stable
- Basic tooling (ping, netstat) built on top of our stack
- Performance tuning specific to IR0 workloads
- Optional crypto/offload extensions
Status: Research/design phase (no borrowed Linux subsystems).
🔧 Driver Subsystem
Modular framework for hardware driver development and management, with support for hot-plugging and automatic device management.
Driver Types:
- Block Devices: Disks, SSDs, storage devices
- Character Devices: Terminals, input devices
- Network Devices: Network cards, WiFi, Bluetooth
- Graphics: GPUs, framebuffers, hardware acceleration
Features:
- Unified driver framework
- Hardware auto-detection
- Integrated power management
- Driver signing and verification
Files: drivers/core.c, drivers/block/, drivers/char/, drivers/net/
🔐 Security System
Comprehensive security framework that protects the kernel and user processes, implementing multiple layers of protection and security auditing.
Security Components:
- Access Control: Role-based access control (RBAC)
- Capability System: Granular capability system
- Seccomp: Syscall filtering for sandboxing
- LSM (Linux Security Modules): Interchangeable security modules
Features:
- ASLR (Address Space Layout Randomization)
- Stack canaries and buffer overflow protection
- Automatic kernel hardening
- Security event auditing
- TPM integration for integrity measurement
Files: security/capability.c, security/seccomp.c, security/lsm/, security/audit.c
⚡ Power Management
Advanced power management system that optimizes battery consumption in mobile devices and reduces energy consumption in servers while maintaining performance.
Power States:
- Suspend to RAM: Fast suspension with instant recovery
- Suspend to Disk: Complete hibernation
- Standby: Low-power standby mode
- Dynamic Frequency Scaling: Dynamic CPU frequency adjustment
Optimizations:
- Intelligent CPU idle management
- Wake-on-LAN and wake-on-timer
- Power capping for servers
- Automatic thermal management
- Battery health monitoring
Files: power/suspend.c, power/cpuidle.c, power/thermal.c, power/battery.c
🎯 Virtualization
Virtualization support is a long-term research item aimed at running alternate OS instances for lab work. Containerization is not on the roadmap for IR0.
Planned Exploration:
- Simple hypervisor hooks inspired by KVM concepts
- Paravirtualized drivers tailored to IR0 guests
- Debug-focused instrumentation rather than production HA features
- GPU/IO passthrough research once the basics are stable
Status: Concept stage; no containers and no running VMs yet.
📊 Monitoring and Debugging
Complete monitoring and debugging system that provides deep visibility into kernel operation and enables real-time problem diagnosis.
Debugging Tools:
- Kprobes: Dynamic insertion points in the kernel
- ftrace: Function and event tracer
- perf: Advanced performance profiler
- eBPF: Dynamic kernel programming
Metrics and Monitoring:
- CPU, memory and I/O profiling
- Network packet tracing
- System call monitoring
- Kernel panic analysis
- Performance counters
Files: kernel/trace/, kernel/debug/, kernel/profiling/, kernel/bpf/
🔧 Device Tree
Hardware description system that allows the kernel to automatically discover and configure hardware devices without needing hardcoded specific drivers.
Features:
- Declarative hardware description
- Support for multiple architectures
- Dynamic overlays for configuration
- UEFI/ACPI firmware compatibility
Benefits:
- Faster boot on embedded systems
- Automatic device configuration
- Cross-platform portability
- Reduction of platform-specific code
Files: drivers/of/, drivers/acpi/, drivers/firmware/
🎮 Graphics and Multimedia
Graphics subsystem that provides hardware acceleration, multi-monitor support and advanced multimedia capabilities.
Graphics Components:
- DRM (Direct Rendering Manager): Modern graphics management
- KMS (Kernel Mode Setting): Display mode configuration
- GEM (Graphics Execution Manager): Graphics memory management
- V4L2: Video4Linux for video capture
Features:
- Support for modern GPUs (NVIDIA, AMD, Intel)
- Hardware video acceleration
- Multi-head display
- HDR and color management
- VR/AR support
Files: drivers/gpu/drm/, drivers/media/, drivers/video/
🔊 Audio Subsystem
Advanced audio system that provides support for multiple formats, real-time audio processing and management of complex audio devices.
Audio Components:
- ALSA (Advanced Linux Sound Architecture): Main audio framework
- PulseAudio: Sound server for users
- JACK: Low-latency professional audio
- ASoC (ALSA System on Chip): Audio for embedded systems
Features:
- HD format support (24-bit, 192kHz)
- 7.1 surround audio
- Noise cancellation
- Bluetooth audio (A2DP, aptX)
- MIDI and audio synthesis
Files: sound/core/, sound/soc/, sound/pci/, sound/usb/
📱 Input/Output Subsystem
Unified input and output system that handles all user interface devices, from keyboards and mice to touchscreens and sensors.
Device Types:
- HID (Human Interface Devices): Keyboards, mice, gamepads
- Touchscreens: Capacitive and resistive touchscreens
- Sensors: Accelerometers, gyroscopes, magnetometers
- Haptic Feedback: Vibration and tactile feedback
Features:
- Multi-touch support
- Gesture recognition
- Accessibility features
- Automatic hot-plugging
- Device power management
Files: drivers/input/, drivers/hid/, drivers/iio/
Downloads